
그룹핑 집합?
그룹핑을 수행하는 특성들의 집합.
아래의 4개의 결과 집합을
하나의 단일 결과집합으로 반환한다고 한다면,
SELECT empid, custid, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY empid, custid
UNION ALL
SELECT empid, NULL, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY empid
UNION ALL
SELECT NULL, custid, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY custid
UNION ALL
SELECT NULL, NULL, SUM(qty) AS SumQty
FROM dbo.Orders;
코드의 길이, 성능이라는 문제를 내포한다.
- 각 그룹핑 집합마다 GROUP BY 절을 지정해야 하며
- 각 쿼리별로 원본 테이블을 스캔하기에 비효율적이다
표준 SQL을 따르면서 같은 쿼리 내에 여러 개의 그룹핑 집합의 정의가 필요한 요구사항을
해결할 수 있는 몇 가지 기능들을 제공하고 있다.
- GROUPING SETS
- CUBE
- ROLLUP
- GROUPING
- GROUPING_ID
GROUPING SETS 서브절
주로 보고서나 DW (데이터웨어 하우스) 환경에서 사용되는 기능으로 강력하게 개선된 기능이 추가된
GROUP BY 절이라 할 수 있다.
동일 쿼리에서 여러 개의 그룹핑 집합을 정의할 수 있다.
정의하고자 하는 그룹핑 집합들을 괄호 내에 쉼표로 구분한 다음, 단순하게 GROUPING SETS 서브절 뒤에 있는 괄호 안에 나열만 하면 된다.
SELECT empid, custid, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY GROUPING SETS (
(empid, custid) ,
(empid) ,
(custid) ,
()
);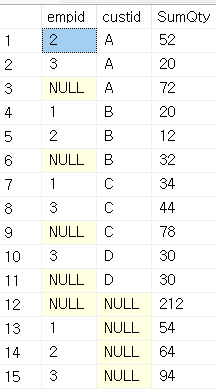
위 쿼리에 비해서,
- 쿼리 길이가 짧다.
- 원본 테이블을 스캔하는 횟수를 최적화시켜서 수행하기에 각 그룹핑 집합마다 별도로 테이블을 스캔하지는 않는다
CUBE 서브절
여러 그룹핑 집합을 정의할 수 있는 축약된 방식을 제공.
CUBE 서브절의 괄호 안에 쉼표로 구분한 멤버들의 목록만 입력하면
입력 멤버를 기준으로 정의될 수 있는 가능한 조합의 모든 그룹핑 집합을 얻을 수 있다.
주어진 모든 요소들을 이용해서 만들 수 있는 그룹핑 집합들의 멱집합을 생성하는 것이라 생각하면 된다.
멱집합? 주어진 집합의 모든 부분 집합의 집합.
SELECT empid, custid, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY CUBE(empid, custid)
ROLLUP 서브절
CUBE절과는 달리, ROLLUP은 입력 멤버들을 기준으로 가능한 모든 그룹핑 집합을 만들어내지 않고,
모든 그룹핑 집합 중 일부만을 만들게 된다.
입력 멤버들 간의 계층관계를 검토 후 계층 관계가 반영된 그룹핑 집합들을 만들게 된다.
ROLLUP (a, b, c)는 a > b > c와 같은 계층 관계 고려해서 4가지 형태의 그룹핑 집합만을 만든다.
GROUPING SETS( (a, b, c), (a, b), (a) , () )로 명시했을 때와 동일하다.
SELECT YEAR(orderdate) AS OrderYear
, MONTH(orderdate) AS OrderMonth
, DAY(orderdate) AS OrderDay
, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY ROLLUP(YEAR(orderdate), MONTH(orderdate), DAY(orderdate))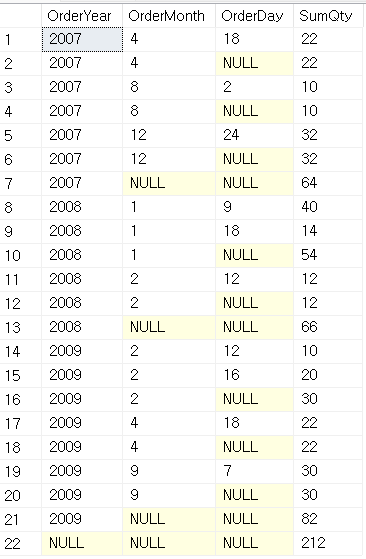
GROUPING 및 GROUPING_ID 함수
여러 개의 그룹핑 집합을 정의하는 단일 쿼리를 사용하는 경우, 결과 행들의 관련도나
그룹핑 집합으로 구분해야 할 필요가 있다.
즉 각 결과 행들이 어떠한 결과 집합에서 왔는지를 확인할 수 있어야 함을 의미한다.
위의 CUBE의 결과를 예시로,
그룹핑 컬럼이 테이블에서 NULL값을 허용하는 것으로 정의되어 있다면,
결과 집합의 NULL값이 데이터에서 온 것인지 그룹핑 집합에 참여하지 않는 멤버들을 나타내기 위한 위치자로부터 온 것인지 구분하기 어렵다.
이 값이 그룹핑 집합과 연관이 있다는 것을 확인하는 방법은 GRUOPING 함수를 이용하는 것이다.
현재 그룹핑 집합의 멤버이면 0, 아니라면 1을 반환.
SELECT GROUPING(empid) AS GrpEmp
, GROUPING(custid) AS GrpCust
, empid, custid, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY CUBE(empid, custid)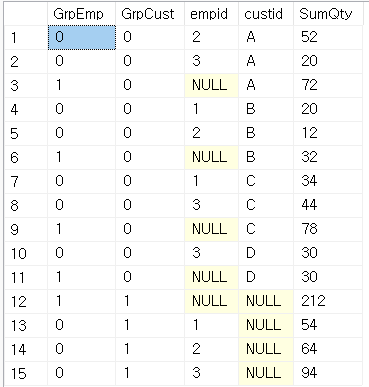
결과 행들과 그룹핑 집합들 중 어떤 것에 연관된 것인지를 찾기위해
NULL값에 의존할 필요가 없다.
GROUPING_ID를 사용하면, 결과 행들과 그룹핑 집합을 구분 짓는 작업을 더 간단히 수행할 수 있다.
입력 값으로 그룹핑 집합에 속해있는 모든 요소를 지정한다 ex) GROUPING_ID(a, b, c, d)
각각의 비트 값이 다른 입력값을 의미하는 정수 비트값을 출력한다.
ex) (a, b, c, d) = 정수 0 ( 0*8 + 0*4 + 0*2 + 0*1)
(a, c) = 정수 5 (0*8 + 1*4 + 0*2 + 1*1)
SELECT GROUPING_ID(empid, custid) AS GroupingSet
, empid, custid, SUM(qty) AS SumQty
FROM dbo.Orders
GROUP BY CUBE(empid, custid)
'프로그래밍&IT > SQL Server (MS-SQL)' 카테고리의 다른 글
| 트랜젝션.Transaction - 원자성, 일관성, 격리성, 영속성 (ACID) (0) | 2024.02.19 |
|---|---|
| 데이터 조작 - 데이터 입력하기 (INSERT VALUES, SELECT, BULK) (1) | 2024.02.18 |
| 데이터 피벗, 언피벗 (Pivot, Unpivot) (1) | 2024.01.27 |
| 윈도우 함수 : 순위, 오프셋, 집계 (1) | 2024.01.25 |
| TOP, OFFSET-FETCH 필터 - 리턴되는 행의 수 제한 (0) | 2023.12.25 |



